เรื่อง Tree
 เนื้อหา
เนื้อหา
- โครงสร้างข้อมูลแบบทรี
- นิยามของทรี
- นิยามที่เกี่ยวข้องกับทรี
- การแทนที่ทรีในหน่วยความจำหลัก
- การแปลงทรีทั่วไปให้เป็นไบนารีทรี
- การท่องไปในทรี
- เอกซเพรสชั่นทรี
- ไบนารีเซิร์ชทรี
จุดประสงค์การเรียนรู้
1. เพื่อให้นักศึกษาทราบโครงสร้างข้อมูลแบบทรี
2. เพื่อให้ทราบนิยามของทรี และที่เกี่ยวข้อง
3. เพื่อให้นักศึกษาทราบวิธีการแทนที่ทรีใน หน่วยความจำหลัก
4. เพื่อให้นักศึกษาทราบการแปลงทรีให้เป็นไบ นารีทรี
5. เพื่อให้นักศึกษาทราบวิธีการท่องไปในทรี
6. เพื่อให้นักศึกษาทราบกระบวนการเอกซเพรสชั่นทรี
7. เพื่อให้นักศึกษาทราบวิธีการไบนารีเซิร์ซทรี
ทรี (Tree)ป็นโครงสร้างข้อมูลที่ความสัมพันธ์ ระหว่าง โหนดจะมัความสัมพันธ์ลดหลั่นกันเป็นลำดับ เช่น (Hierarchical Relationship) ได้มีการนำรูปแบบทรีไปประยุกต์ใช้ในงาน ต่าง ๆ อย่างแพร่หลาย สวนมากจะใชสำหรับแสดง ความสัมพันธ์ระหว่างข้อมูล เช่น แผนผังองค์ประกอบของหน่วยงานต่าง ๆ โครงสร้างสารบัญหนังสือ เป็นต้นแต่ละโหนดจะมีความสัมพันธ์กับ โหนดในระดับที่ต่ำลงมา หนึ่งระดับได้หลาย ๆโหนด เรียกโหนดดั้งกล่าวว่า โหนดแม่(Parent orMother Node)โหนดที่อยู่ต่ำกว่าโหนดแม่อยู่หนึ่งระดับเรียกว่า โหนดลูก (Child or Son Node)โหนดที่อยู่ในระดับสูงสุดและไม่มีโหนดแม่เรียกว่า โหดราก (Root Node) Data Structure โหนดที่มีโหนดแม่เป็นโหนดเดียวกัน รียกว่า โหนดพี่น้อง (Siblings)โหนดที่ไม่มีโหนดลูก เรียกว่า โหนดใบ (Leave Node)เส้นเชื่อมแสดงความสัมพันธ์ระหว่าง โหนดสองโหนดเรียกว่า กิ่ง (Branch)
นิยามของทรี1. นิยามทรีด้วยนิยามของกราฟ ทรี คือ กราฟที่ต่อเนื่องโดยไม่มีวงจรปิด (loop)ในโครงสร้าง โหนดสองโหนด ใดๆในทรีต้องมีทางตัดต่อกันทางเดียวเท่านั้น และทรีที่มี N โหนด ต้องมีกิ่ง ทั้งหมด N-1 เส้น การเขียนรูปแบบทรี อาจเขียนได้ 4
 2. นิยามทรีด้วยรูปแบบรีเคอร์ซีฟทรีประกอบด้วยสมาชิกที่เรียกว่าโหนด โดยที่ ถ้าว่าง ไม่มีโหนดใด ๆ เรียกว่า นัลทรี (Null Tree)และถามโหนดหนึ่งเป็นโหดราก ส่วนที่เหลือจะแบ่งเป็น ทรีย่อย (Sub Tree)T1, T2, T3,…,Tk โดยที่ k>=0 และทรีย่อยต้องมีคุณสมบัติเป็นทรี
2. นิยามทรีด้วยรูปแบบรีเคอร์ซีฟทรีประกอบด้วยสมาชิกที่เรียกว่าโหนด โดยที่ ถ้าว่าง ไม่มีโหนดใด ๆ เรียกว่า นัลทรี (Null Tree)และถามโหนดหนึ่งเป็นโหดราก ส่วนที่เหลือจะแบ่งเป็น ทรีย่อย (Sub Tree)T1, T2, T3,…,Tk โดยที่ k>=0 และทรีย่อยต้องมีคุณสมบัติเป็นทรี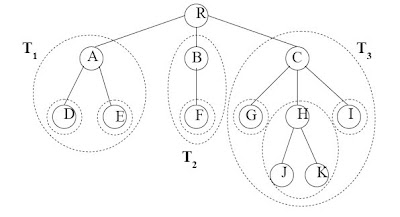 นิยามที่เกี่ยวข้องกับทรี1.ฟอร์เรสต์ (Forest) หมายถึง กลุ่มของทรีที่เกิดจากการเอาโหนดรากของทรีออกหรือเซตของทรีทแยกจากกัน (Disjoint Trees)
นิยามที่เกี่ยวข้องกับทรี1.ฟอร์เรสต์ (Forest) หมายถึง กลุ่มของทรีที่เกิดจากการเอาโหนดรากของทรีออกหรือเซตของทรีทแยกจากกัน (Disjoint Trees)
 2.ทรีที่มีแบบแผน (Ordered Tree) หมายถึง ทรีที่โหนดต่าง ๆ ในทรีนั้นมี ความสัมพันธ์ที่แน่นอน เช่น ไปทางขวาไปทางซ้าย เป็นต้น
2.ทรีที่มีแบบแผน (Ordered Tree) หมายถึง ทรีที่โหนดต่าง ๆ ในทรีนั้นมี ความสัมพันธ์ที่แน่นอน เช่น ไปทางขวาไปทางซ้าย เป็นต้น
3.ทรีคล้าย (Similar Tree) คือทรีที่มีโครงสร้างเหมือนกันหรือทรีที่มีรูปร่างของทรีเหมือนกันโดยไม่คำนึงถึงข้อมูลที่อยู่ในแต่ละโหนด 4.ทรีเหมือน (Equivalent Tree) คือ ทรีที่เหมือนกันโดยสมบูรณ์โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน
4.ทรีเหมือน (Equivalent Tree) คือ ทรีที่เหมือนกันโดยสมบูรณ์โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน
4.ทรีเหมือน (Equivalent Tree) คือ ทรีที่เหมือนกันโดยสมบูรณ์โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน ในรูปโหนด “B” มีกำลังเป็น 1 เพราะมีทรีย่อย คือ {“D”}ส่วนโหนด “C” มีค่ากำลังเป็นสองเพราะมีทรีย่อย คือ {“E”, “G”, “H”, “I”} และ {“F”}
ในรูปโหนด “B” มีกำลังเป็น 1 เพราะมีทรีย่อย คือ {“D”}ส่วนโหนด “C” มีค่ากำลังเป็นสองเพราะมีทรีย่อย คือ {“E”, “G”, “H”, “I”} และ {“F”}6.ระดับของโหนด (Level of Node) คือ ระยะทางในแนวดิ่งของโหนดนั้น ๆ ที่อยู่ห่างจากโหนดราก เมื่อกำหนดให้ โหนดรากของทรีนั้นอยู่ระดับ 1 และกิ่งแต่ละกิ่งมีความเท่ากันหมด คือ ยาวเท่ากับ 1หน่วยซึ่งระดับของโหนดจะเท่ากับจำนวนกิ่งที่น้อยที่สุดจากโหนดรากไปยังโหนดใด ๆ บวกด้วย 1และจำนวนเส้นทางตามแนวดิ่งของโหนดใด ๆ ซึ่งห่างจากโหนดราก เรียกวา ความสูง (Height)หรือความ ลึก (Depth)

การแทนที่โครงสร้างข้อมูลแบบทรีในความจำหลักจะมีพอยเตอร์เชื่อมโยงจากโหนดแม่ไปยังโหนดลูก แต่ละโหนดต้องมีลิงค์ฟิลด์เพื่อเก็บที่อยู่ของโหนดลูกต่าง ๆ นั้นคือจำนวน ลิงคฟิลด์ของแต่ละโหนดขึ้นอยู่กับจำนวนของโหนดลูกการแทนที่ทรี ซึ่งแต่ละโหนดมีจำนวนลิงค์ฟิลด์ไม่เท่ากันทำให้ยากต่อการปฏิบัติการ วิธีการแทนที่ที่ง่ายที่สุดคือ ทำให้แต่ละโหนดมีจำนวนลิงคฟิลด์เท่ากันโดยอาจใช่วิธีการต่อไปนี้
1.โหนดแต่ละโหนดเก็บพอยเตอร์ชี้ไปยังโหนดลูก ทุกโหนด การแทนที่ทรีด้วยวิธีนี้จะให้จำนวนฟิลด์ในแต่ละ โหนดเท่ากันโดยกำหนดใหม่ขนาดเท่ากับจำนวนโหนดลูกของโหนดที่มีลูกมากที่สุด โหนดใดไม่มีโหลดลูกก็ให้ค่า พอยเตอร์ในลิงค์ฟิลด์นั้นมีค่าเป็น Null และให้ลิงค์ฟิลด์แรกเก็บค่าพอยเตอร์ชี้ไปยังโหนด ลูกลำดับ ที่หนึ่ง ลิงค์ฟิลด์ที่สองเก็บค่าพอยเตอร์ชี้ไปยังโหนดลูก ลำดับที่สองและลิงค์ฟิลด์อื่นเก็บค่าพอยเตอร์ของโหนดลูก ลำดับถัดไปเรื่อย ๆ

การแทนทรีด้วยโหนดขนาดเท่ากันค่อนข้างใช้เนื้อที่จำนวนมากเนื่องจากแต่ละโหนดมี จำนวนโหนดลูกไม่เท่ากันหรือบางโหนดไม่มี โหนดลูกเลยถ้าเป็นทรีที่แต่ละโหนดมีจำนวนโหนดลูกที่แตกต่างกันมากจะเป็นการสิ้นเปลือง เนื้อที่ในหน่วยความจำโดยเปล่าประโยชน์
2.แทนทรีด้วยไบนารีทรีเป็นวิธีแก้ปัญหาเพื่อลดการ สิ้นเปลืองเนื้อที่ในหน่วยความจำก็คือ กำหนดลิงค์ฟิลด์ใหม่จำนวนน้อยที่สุดเท่าที่จำเป็นเท่านั้นโดยกำหนดให้แต่ละโหนดมีจำนวนลิงค์ฟิลด์สองลิงค์ฟิลด์-ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกคนโต-ลิงค์ฟิลด์ทสองเก็บที่อยู่ของโหนดพี่น้องที่เป็นโหนดถัดไปโหนดใดไม่มีโหนดลูกหรือไม่มีโหนดพี่น้องให้ค่าพอยนเตอร์ใน ลิงค์ฟิลด์มีค่าเป็น Null


ระดับ 1 มีจำนวนโหนด 1 โหนด
ระดับ 2 มีจำนวนโหนด 3 โหนด
ระดับ 3 มีจำนวนโหนด 7 โหนด
ระดับ L มีจำนวนโหนด 2L - 1โหนด
นั้นคือ จำนวนโหนดทั้งหมดในทรีสมบูรณ์ที่ มี L ระดับ สามารถคำนวณได้จากสูตรดั้งนี้

ขั้นตอนการแปลงทรีทั่วๆ ไปให้เป็นไบนารีทรี มีลำดับขั้นตอนการแปลง ดั้งต่อไปนี้
1. ให้โหนดแม่ชี้ไปยังโหนดลูกคนโต แล้วลบความสัมพันธ์ ระหว่างโหนดแม่และโหนดลูกอื่น ๆ
2. ให้เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
3. จบให้ทรีย่อยทางขวาเอียงลงมา 45 องศา


การท่องไปในไบนารีทรี
ปฏิบัติการที่สำคัญในไบนารีทรี คือ การท่องไปในไบนารีทรี (Traversing Binary Tree) เพื่อเข้าไปเยือนทุก ๆโหนดในทรี ซึ่งวิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบแผน สามารถเยือนโหนดทุก ๆโหนด ๆ ละหนึ่งครั้งวิธีการท่องไปนั้นมีด้วยกันหลายแบบแล้วแต่ว่าต้องการลำดับขั้นตอนการเยือนอย่างไร โหนดที่ถูกเยือนอาจเป็นโหนดแม่ (แทนด้วย N)ทรีย่อยทางซ้าย (แทนด้วย L)หรือทรีย่อยทางขวา (แทนด้วย R)
มีวิธีการท่องเข้าไปในทรี 6 วิธี คือ NLR LNR LRN NRL RNL และ RLN แต่วิธีการท่องเข้าไปไบนารีทรีที่นิยมใช้กันมากเป็นการท่องจากซ้ายไปขวา 3 แบบแรกเท่านั้นคือ NLR LNR และ LRN ซึ่งลักษณะการนิยามเป็นนิยามแบบ รีเคอร์ซีฟ(Recursive) ซึ่งขั้นตอนการท่องไปในแต่ละแบบมีดังนี้
1. การท่องไปแบบพรีออร์เดอร์(Preorder Traversal) เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธีNLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์

(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
 3. การท่องไปแบบโพสออร์เดอร์(Postorder Traversal)เป็นการเดินเข้าไปเยือนโหนดต่าง ๆในทรีด้วยวิธี LRN มีขั้นตอนการเดินดังต่อไปนี้
3. การท่องไปแบบโพสออร์เดอร์(Postorder Traversal)เป็นการเดินเข้าไปเยือนโหนดต่าง ๆในทรีด้วยวิธี LRN มีขั้นตอนการเดินดังต่อไปนี้(1) ท่องไปในทรีย่อยทางซ้ายแบบโพสต์ออร์เดอร์
(2) ท่องไปในทรีย่อยทางขวาแบบโพสต์ออร์เดอร์

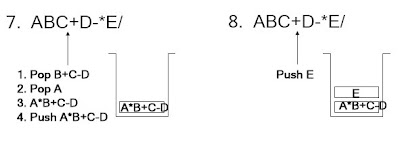
เป็นการนำเอาโครงสร้างทรีไปใช้เก็บนิพจน์ทางคณิตศาสตร์โดยเป็นไบนารีทรี ซึ่งแต่ละโหนดเก็บตัวดำเนินการ (Operator) และและตัวถูกดำเนินการ(Operand) ของนิพจน์คณิตศาสตร์นั้น ๆ ไว้ หรืออาจจะเก็บค่านิพจน์ทางตรรกะ (Logical Expression)นิพจน์เหล่านี้เมื่อแทนในทรีต้องคำนึงลำดับขั้นตอนในการคำนวณตามความสำคัญของเครื่องหมายด้วยโดยมีความสำคัญตามลำดับดังนี้
- ฟังก์ชัน
- วงเล็บ
- ยกกำลัง
- เครื่องหมายหน้าเลขจำนวน (unary)
- คูณ หรือ หาร
- บวก หรือ ลบ
- ถ้ามีเครื่องหมายที่ระดับเดียวกันให้ทำจากซ้ายไปขวา
การแทนนิพจน์ในเอ็กซ์เพรสชันทรี ตัวถูกดำเนินการจะเก็บอยู่ที่โหนดใบส่วนตัวดำเนินการจะเก็บในโหนดกิ่งหรือโหนดที่ไม่ใช่โหนดใบเช่น นิพจน์ A + B สามารถแทนในเอ็กซ์เพรสชันทรีได้ดังนี้


ไบนารีเซิร์ชทรี
ไบนารีเซิร์ชทรี (Binary Search Tree)เป็นไบนารีทรีที่มีคุณสมบัติที่ว่าทุก ๆ โหนดในทรี ค่าของโหนดรากมีค่ามากกว่าค่าของทุกโหนดในทรีย่อยทางซ้าย และมีค่าน้อยกว่าหรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวาและในแต่ละทรีย่อยก็มี คุณสมบัติเช่นเดียวกัน

ปฏิบัติการในไบนารีเซิร์ชทรี ปฏิบัติการเพิ่มโหนดเข้าหรือดึงโหนดออกจากไบนารีเซิร์ชทรีค่อนข้างยุ่งยากกว่าปฏิบัติการในโครงสร้างอื่น ๆเนื่องจากหลังปฏิบัติการเสร็จเรียบร้อยแล้วต้องคำนึงถึงความเป็นไบนารีเซิร์ชทรีของทรีนั้นด้วยซึ่งมีปฏิบัติการดังต่อไปนี้
(1) การเพิ่มโหนดในไบนารีเซิร์ชทรี การเพิ่มโหนดใหม่เข้าไปในไบนารีเซิร์ชทรี ถ้าทรีว่างโหนดที่เพิ่มเข้าไปก็จะเป็นโหนดรากของทรี ถ้าทรีไม่ว่างต้องทำการตรวจสอบว่าโหนดใหม่ที่เพิ่มเข้ามานั้นมีค่ามากกว่าหรือน้อยกว่าค่าที่โหนดราก ถ้ามีค่ามากกว่าหรือเท่ากันจะนำโหนดใหม่ไปเพิ่มในทรีย่อยทางขวาและถ้ามีค่าน้อยกว่านำโหนดใหม่ไปเพิ่มในทรีย่อยทางซ้ายในทรีย่อยนั้นต้องทำการเปรียบเทียบในลักษณะเดียวกันจนกระทั่งหาตำแหน่งที่สามารถเพิ่มโหนดได้ ซึ่งโหนดใหม่ที่

(2) การดึงโหนดในไบนารีเซิร์ชทรีหลังจากดึงโหนดที่ต้องการออกจากทรีแล้วทรีนั้นต้องคงสภาพไบนารีเซิร์ชทรีเหมือนเดิมก่อนที่จะทำการดึงโหนดใด ๆ ออกจากไบนารีเซิร์ชทรี ต้องค้นหาก่อนว่าโหนดที่ต้องการดึงออกอยู่ที่ตำแหน่งไหนภายในทรีและต้องทราบที่อยู่ของโหนดแม่โหนดนั้นด้วยแล้วจึงทำการดึงโหนดออกจากทรีได้ ขั้นตอนวิธีดึงโหนดออกอาจแยกพิจารณาได้ 3กรณีดังต่อไปนี้
ก. กรณีโหนดที่จะดึงออกเป็นโหนดใบการดึงโหนดใบออกในกรณีนี้ทำได้ง่ายที่สุดโดยการดึงโหนดนั้นออกได้ทันที เนื่องจากไม่กระทบกับโหนดอื่นมากนัก วิธีการก็คือให้ค่าในลิงค์ฟิลด์ของโหนดแม่ซึ่งเก็บที่อยู่ของโหนดที่ต้องการดึงออกให้มีค่าเป็น Null

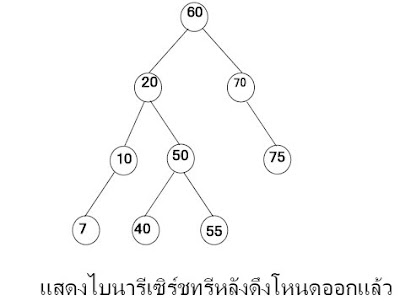 ข. กรณีโหนดที่ดึงออกมีเฉพาะทรีย่อยทางซ้ายหรือทรีย่อยทางขวาเพียงด้านใดด้านหนึ่ง วิธีการดึงโหนดนี้ออกสามารถใช้วิธีการเดียวกับการดึงโหนดออกจากลิงค์ลิสต์ โดยให้โหนดแม่ของโหนดที่จะดึงออกชี้ไปยังโหนดลูกของโหนดนั้นแทน
ข. กรณีโหนดที่ดึงออกมีเฉพาะทรีย่อยทางซ้ายหรือทรีย่อยทางขวาเพียงด้านใดด้านหนึ่ง วิธีการดึงโหนดนี้ออกสามารถใช้วิธีการเดียวกับการดึงโหนดออกจากลิงค์ลิสต์ โดยให้โหนดแม่ของโหนดที่จะดึงออกชี้ไปยังโหนดลูกของโหนดนั้นแทน ค. กรณีโหนดที่ดึงออกมีทั้งทรีย่อยทางซ้ายและทรีย่อยทางขวาต้องเลือกโหนดมาแทนโหนดที่ถูกดึงออก โดยอาจจะเลือกมาจากทรีย่อยทางซ้ายหรือทรีย่อยทางขวาก็ได้
ค. กรณีโหนดที่ดึงออกมีทั้งทรีย่อยทางซ้ายและทรีย่อยทางขวาต้องเลือกโหนดมาแทนโหนดที่ถูกดึงออก โดยอาจจะเลือกมาจากทรีย่อยทางซ้ายหรือทรีย่อยทางขวาก็ได้- ถ้าโหนดที่มาแทนที่เป็นโหนดที่เลือกจากทรีย่อยทางซ้ายต้องเลือกโหนดที่มีค่ามากที่สุดในทรีย่อยทางซ้ายนั้น
- ถ้าโหนดที่จะมาแทนที่เป็นโหนดที่เลือกมาจากทรีย่อยทางขวา ต้องเลือกโหนดที่มีค่าน้อยที่สุดในทรีย่อยทางขวานั้น



1.โครงสร้างข้อมูลแบบต้นไม้เป็นโครงสร้างชนิดใด
ก. ชนิดเชิงเส้น
ข. ชนิดไม่เชิงเส้น
ค. ชนิดตัดสินใจเลือก
ง. ชนิดทำงานซ้ำ
2. โหนดพิเศษโหนดหนึ่งที่อยู่บนสุดแรกเรียกว่าอะไร
ก. Father
ข. Subtree
ค. Leat Node
ง. Root Node
3. Level มีความหมายตรงกับข้อใด
ก. รูท
ข. ดีกรีของโหนด
ค. โหนดที่เป็นใบ
ง. ระดับของโหนด
4. ดีกรีของโหนดคืออะไร
ก. รูทโหนด
ข. จำนวนต้นไม้ 1 ต้น
ค. ต้นไม้แบบพรีออเดอร์
ง. จำนวนต้นไม้ย่อยของโหนดนั้น
5. ป่าไม้ในโครงสร้างข้อมูลแบบต้นไม้ หมายถึงสิ่งใด
ก. กลุ่มของต้นไม้
ข. ต้นไม้ย่อยซ้าย
ค. ต้นไม้ย่อยขวา
ง. การดูแลต้นไม้
6. โครงสร้างข้อมูลแบบต้นไม้ มีลักษณะคล้ายสิ่งใด
ก. ใบไม้
ข. รากของต้นไม้
ค. ลำต้นของต้นไม้
ง. กิ่งก้านของต้นไม้
7. ต้นไม้ธรรมชาติจะงอกจากล่างขึ้นบน ส่วนโครงสร้างข้อมูลแบบต้นไม้นั้นจะเจริญเติบโตอย่างไร
ก.จากล่างไปบน
ข. จากบนลงล่าง
ค. จากซ้ายไปขวา
ง. จากขวาไปซ้าย
8. ต้นไม้ Binary ที่แต่ละโหนดภายในจะมีโหนดย่อยซ้ายโหนดย่อยขวาและโหนดใบหมายถึงต้นไม้แบบใด
ก. ต้นไม้ไบนารีคู่
ข. ต้นไม้ไบนารีเดี่ยว
ค. ต้นไม้ไบนารีแบบสมบูรณ์
ง. ต้นไม้ไบนารีแบบไม่สมบูรณ์
9. ข้อใดไม่ใช่การแทนต้นไม้ไบนารีในหน่วยความจำ
ก. การแทนโดยอาศัยพอยน์เตอร์
ข การแทนโดยอาศัยแอดเดรสของโหนด
ค. การแทนแบบวีแควนเชียล
ง. การแทนแบบลำดับชั้น
10. LVR คือวิธีการเดินเข้าแบบใด
ก. แบบพรีออร์เดอร์
ข. แบบอินออร์เดอร์
ค. แบบโพสต์ออร์เดอร์
ง. ไม่มีข้อใดถูก
เฉลย 1.ข 2.ง 3.ง 4.ง 5.ก 6.ง 7.ข 8.ค 9.ง 10.ข





















 การคำนวณนิพจน์ทางคณิตศาสตร์ในการเขียนนิพจน์ทางคณิตศาสตร์เพื่อการคำนวณจะต้องคำนึงถึงลำดับความสำคัญของเครื่องหมายสำหรับการคำนวณด้วยโดยทั่วไปนิพจน์ทางคณิตศาสตร์สามารถเขียนได้ 3 รูปแบบ คือ
การคำนวณนิพจน์ทางคณิตศาสตร์ในการเขียนนิพจน์ทางคณิตศาสตร์เพื่อการคำนวณจะต้องคำนึงถึงลำดับความสำคัญของเครื่องหมายสำหรับการคำนวณด้วยโดยทั่วไปนิพจน์ทางคณิตศาสตร์สามารถเขียนได้ 3 รูปแบบ คือ